这是一个持续更新的读书笔记.

书名: Designing Data-Intensive Applications: The Big Ideas Behind Reliable, Scalable, and Maintainable Systems(DDIA).
原书网站: link
大神推荐: 在做程序员的道路上,你掌握了什么概念或技术使你感觉自我提升突飞猛进? - 阿莱克西斯的回答 - 知乎
……… 脑子里或者说工具箱里里的东西很多,但是却非常乱,概念实现经常记混,我经常在想:如果能总结归类,用更科学的方法去记住所有我学过的技术,那就好了。。。然后我就遇到了这本书,我读了三遍,然后感觉一切都理顺了… 如果我先读了这本书,才去学上边这些东西,那么我花费的时间将是原来的3分之一到5分之一左右。这本书在广度和一定程度的深度(如果对进一步深度有要求,可以读完此书的reference)上,概括和总结了数据系统,分布式或非分布式环境下面临的本质问题,和解决方案的分类,看完这本,我开始理解了“为什么”这么多的分布式系统要这么设计。而这本书上千的引用论文,给我指明了一条系统学习理论的明路 ………
Chapter 1
3 goals of Data Intensive Application(DIA)
Reliability
Continuing to work correctly, even when things go wrong.
- “Wrong”
- Hardware: rare, little correlation. Remedy: Hardware duplication
- Software: wrong assumption about the system/bugs
- Human: most frequent.
- Remedy:
-
- Good system design
- Decouple sensitive environment/sandbox
- Test
- Easy and quick recovery
- Good monitoring
- Good management practice
-
- Remedy:
Scalability
system’s ability to cope with increased load.
- Metrics for “Load”
- Latency/response time of Xth percentile (usually 99th Percentile)
- Best to estimate continuously over a window (t-digest/HdrHistogram)
- Throughput
- Latency/response time of Xth percentile (usually 99th Percentile)
Maintainability
-
Operability: Make it easy for operations teams to keep the system running smoothly.
-
Simplicity; Make it easy for new engineers to understand the system
-
Evolvability: Make it easy for engineers to make changes to the system in the future
Chapter 2: Data Structure
Hash Indexes
-
Key idea: In-memory hashtable of keys, whereby values are byte offset of its on-disk stored file. Log-structured means append-only.
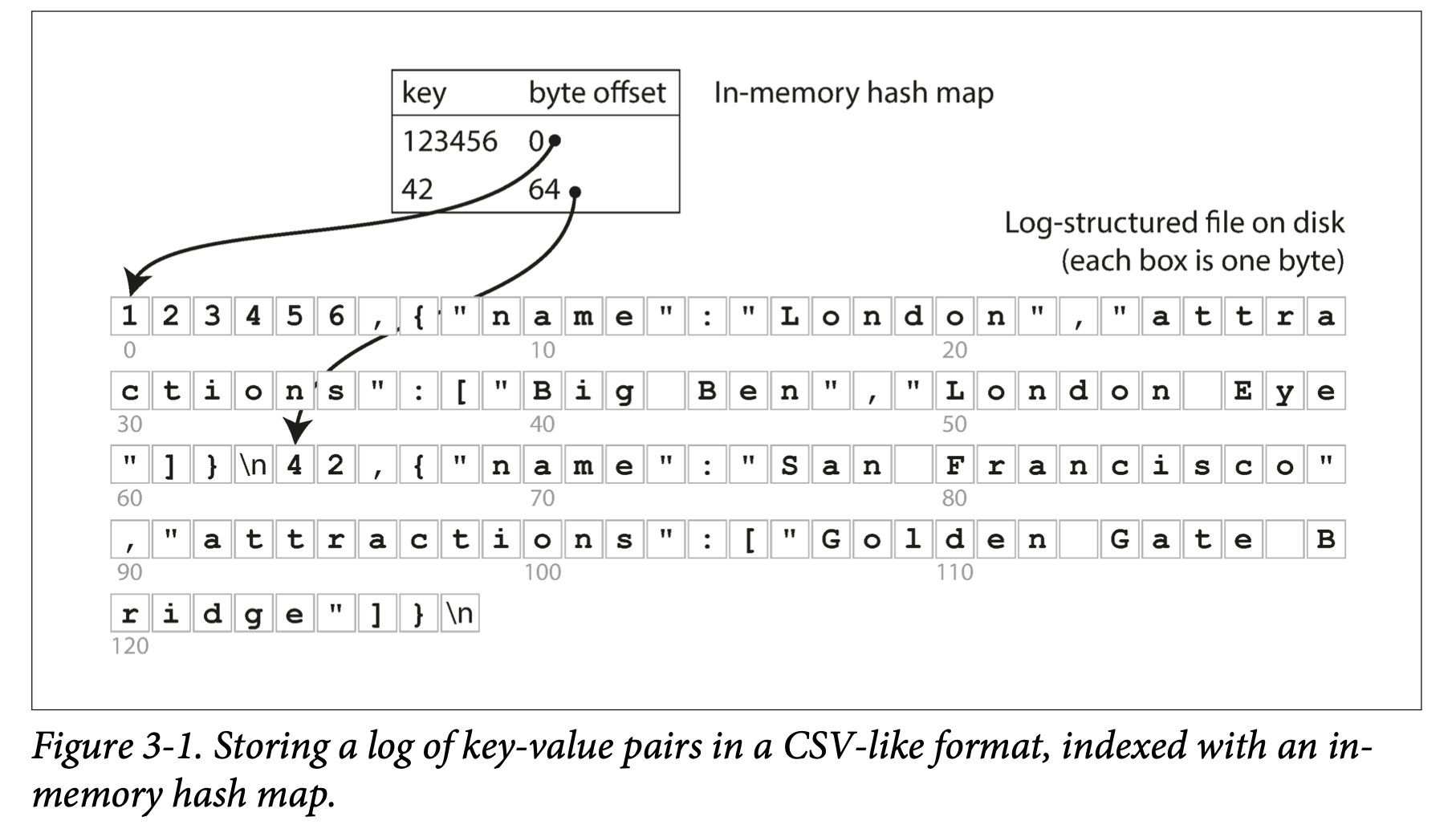
-
How to avoid run out of disk space (since append-only) : break log into segments, and each segments has its own in-memory hashtable. We close a segment and open a new segment when size gets too big.
- How to keep number of segments small: merging old segments together by discarding old values of the same key.
- How to retrieve value of a key: firstly look-up in the newest in-memo hashtable, then old ones.
SSTable
-
Key idea: make key-value pairs sorted by key. So in-memo hashtable can only keep a small number of keys.
-
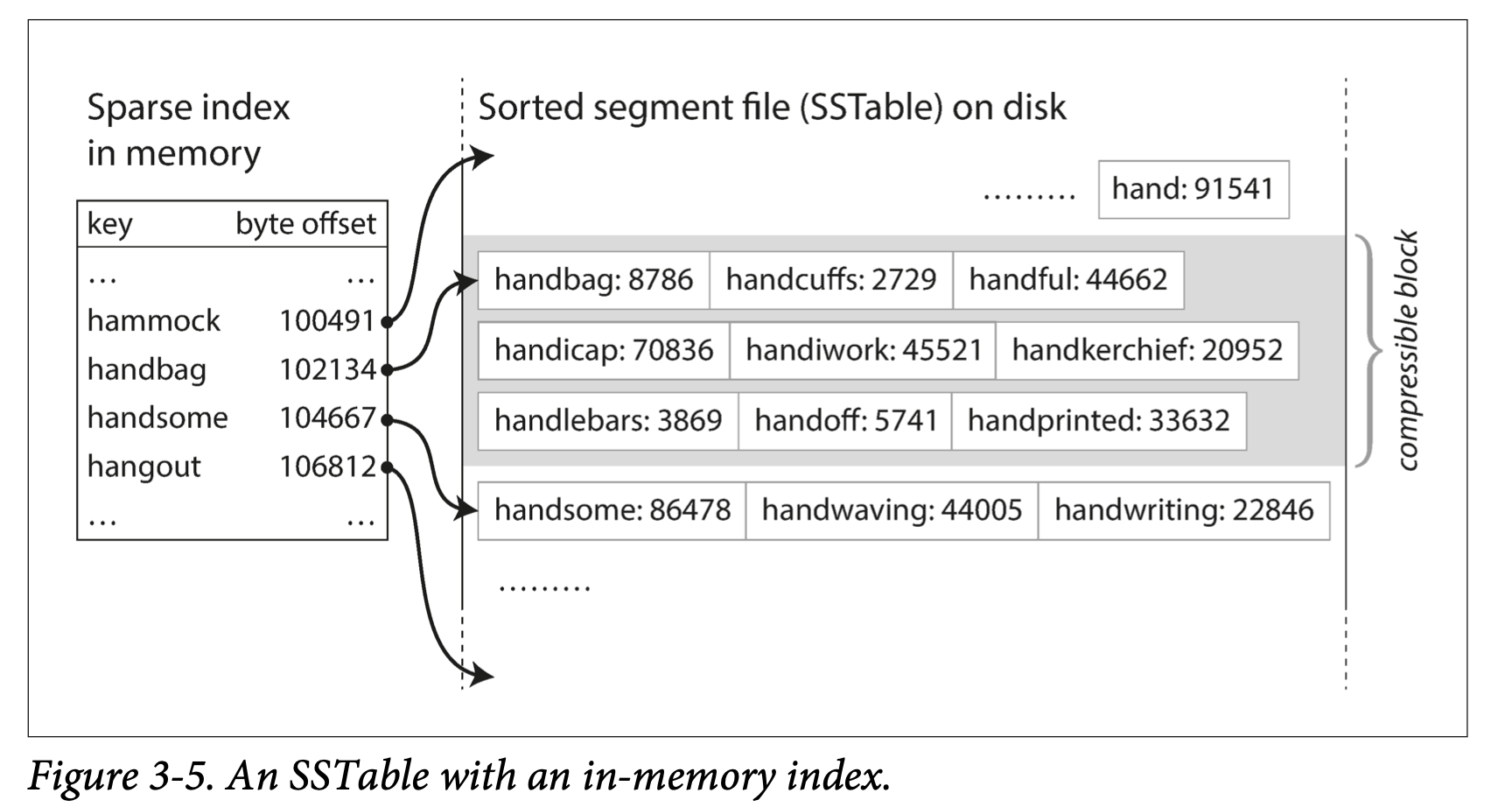
- Constructing and maintaining SSTables/Memtable
- Write to in-memory balance tree structure, also called “memtable”
- When memtable gets too big, save it to disk as SSTable. Create a new memtable.
- Read request will search memtable, if not found then in newest SSTable
- Need background process merging and compacting SSTable
- Keep a log of events in case of crash. Refresh log once memtable is written out as an SSTable
-
Optimization
- Slow to know a key not in DB: Bloom filter
B-Tree
Key idea: Data are break-up into fix-size pages. For non-leaf pages, each one has sorted indexes and pointers to children pages. Each leaf page contains indexes and their values. All data are on disk
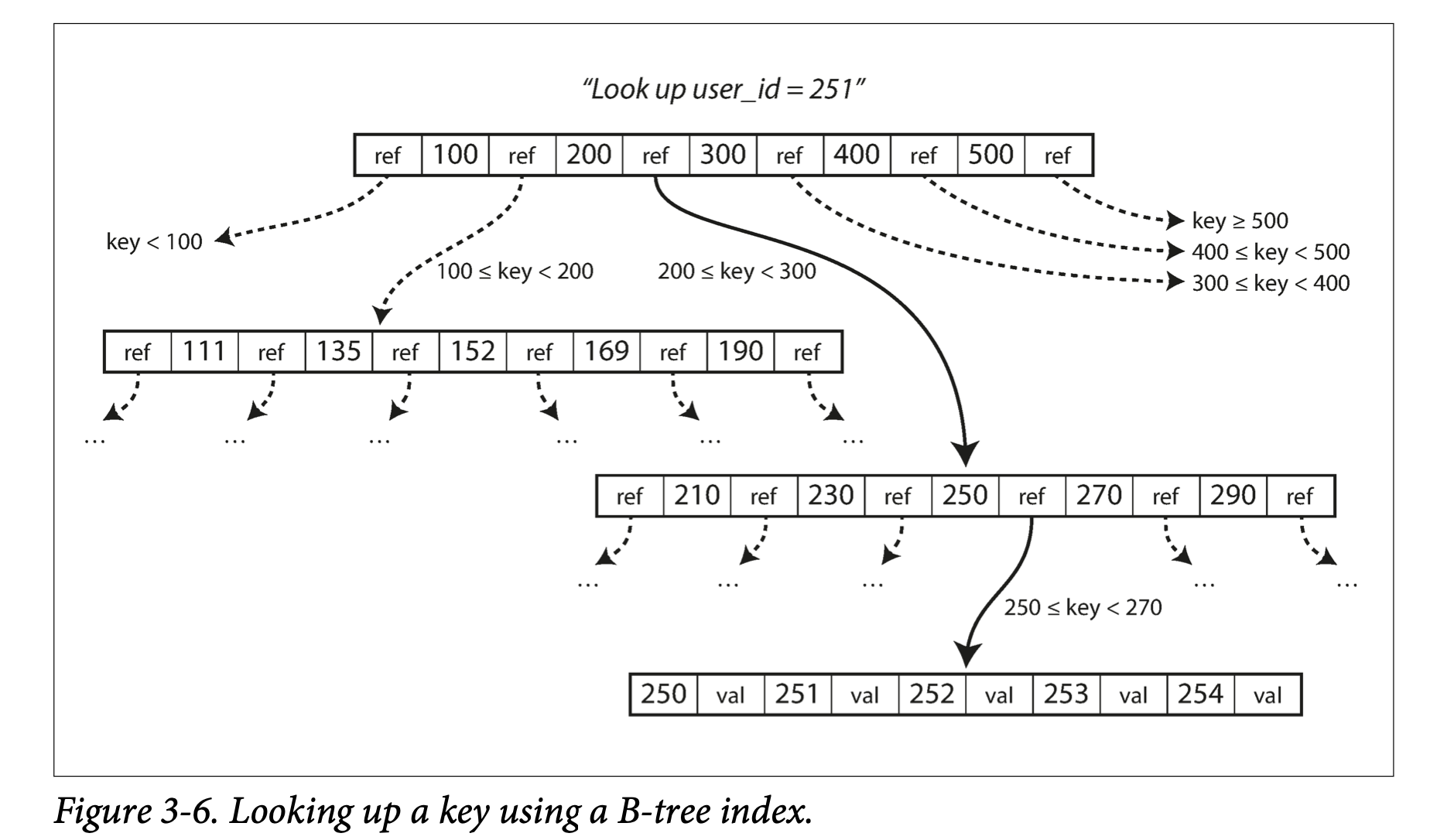
-
Look-up: n-ary search
-
Insert: look-up then insert. If full, split into two pages.
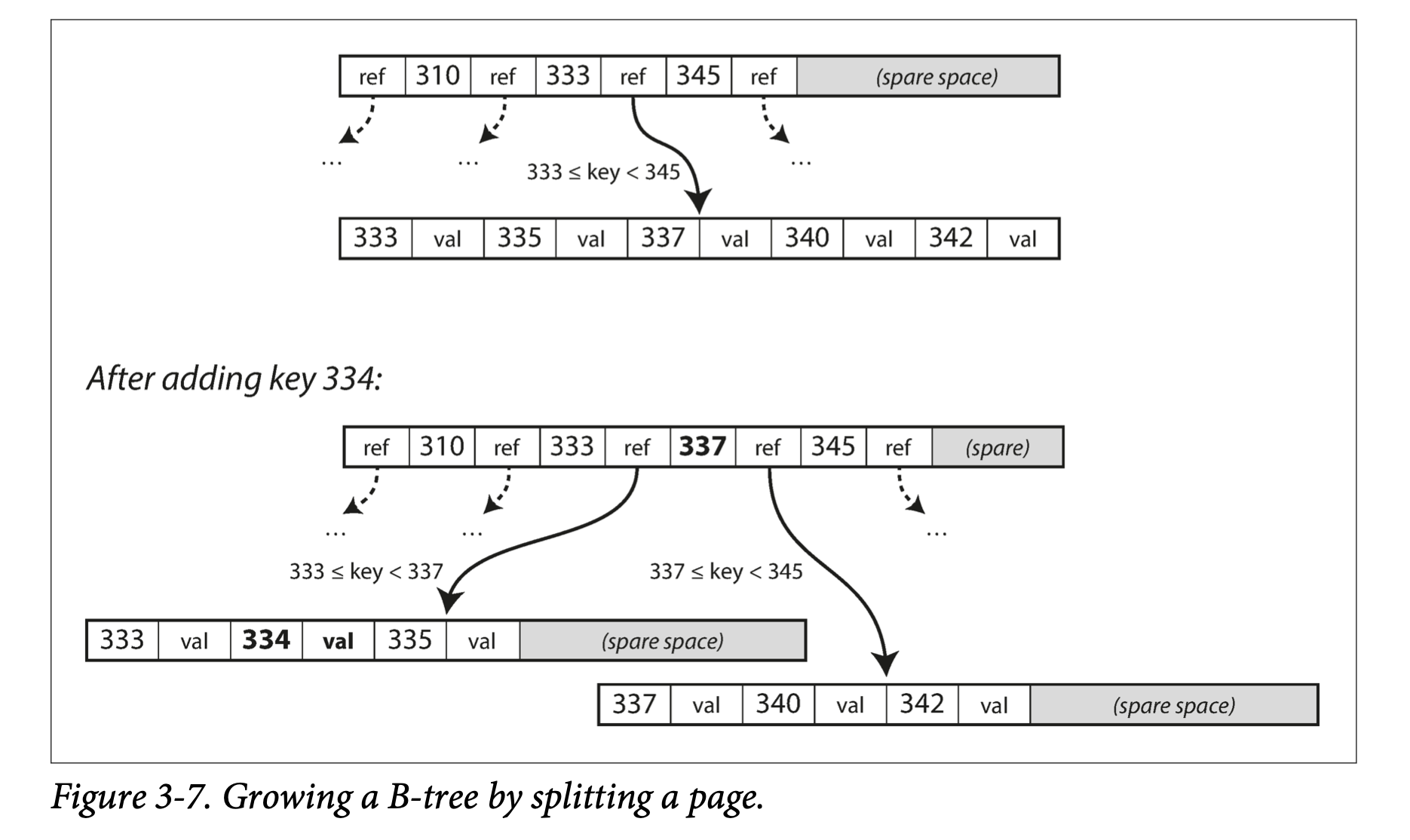
-
Write-ahead log(WAL):
an append-only file to which every B-tree modification must be written before it can be applied to the pages of the tree itself. When the data‐ base comes back up after a crash, this log is used to restore the B-tree back to a con‐ sistent state
B-Tree vs. LSM-Tree
- LSM-Tree ✔️B-Tree ✖️:
- B-Tree must write data twice (WAL and on-disk tree page)
- LSM-Tree sometimes has lower write amplification. B-Tree often needs to write several pages but LSM-Tree sequentially write compact SSTables.
- B-Tree leaves unused fragmentation
- LSM-Tree ✖️ B-Tree ✔️:
- LSM-Tree’s compaction process affects concurrent access of disk. B-Tree more predictable.
- At high write throughput. compaction uses up disk bandwidth
- If not configured properly, LSM-Tree has too many SSTable that uses up disk space and slow down reads
- B-Tree has exactly one index in one place, which makes it easy to impose transactional isolation using locks on keys.
- B-Tree provide consistently good performance for many workloads.
Other Index Structures
-
Heap file: referring value outside indexes
-
What: data with no order
-
Why: value could be the actual row (document, vertex), or it could be a reference to the row stored in heap file.
-
https://blog.csdn.net/qq910894904/article/details/39312901
-
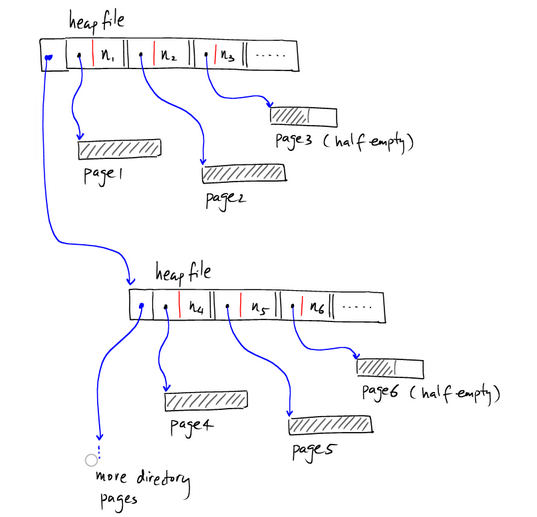
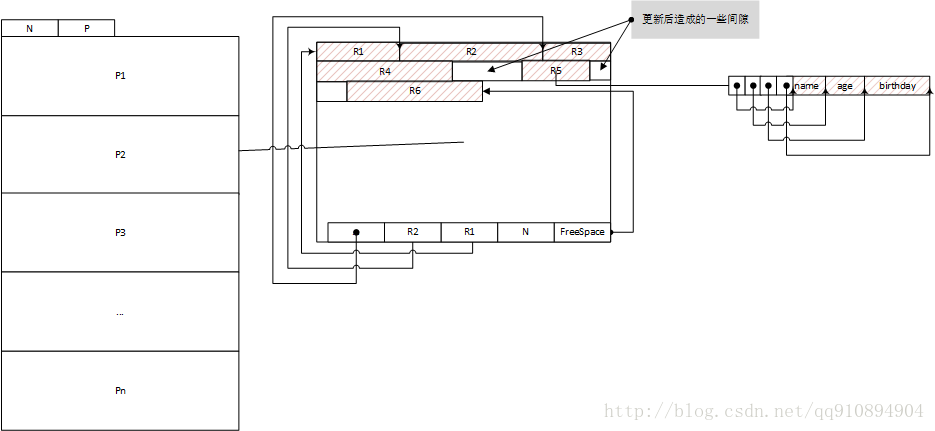
-
-
Clustered/Non-clustered index/Covering index
- Store row directly within index. e.g. in MySQL’s InnerDB, the primary key of a table is default a clustered index
- Covering index: A compromise between a clustered index (storing all row data within the index) and a nonclustered index (storing only references to the data within the index)
Chapter 5 Data Duplication
Leader based/master-slave
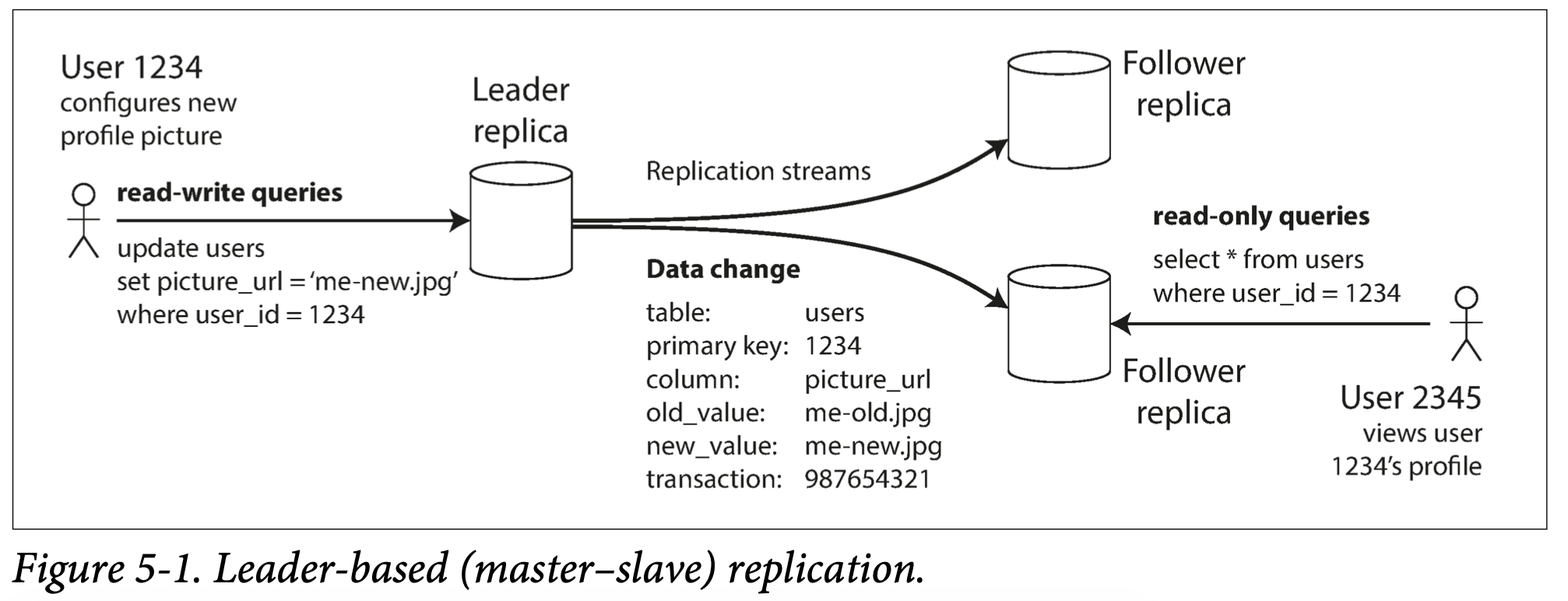
Synchronous Versus Asynchronous Replication
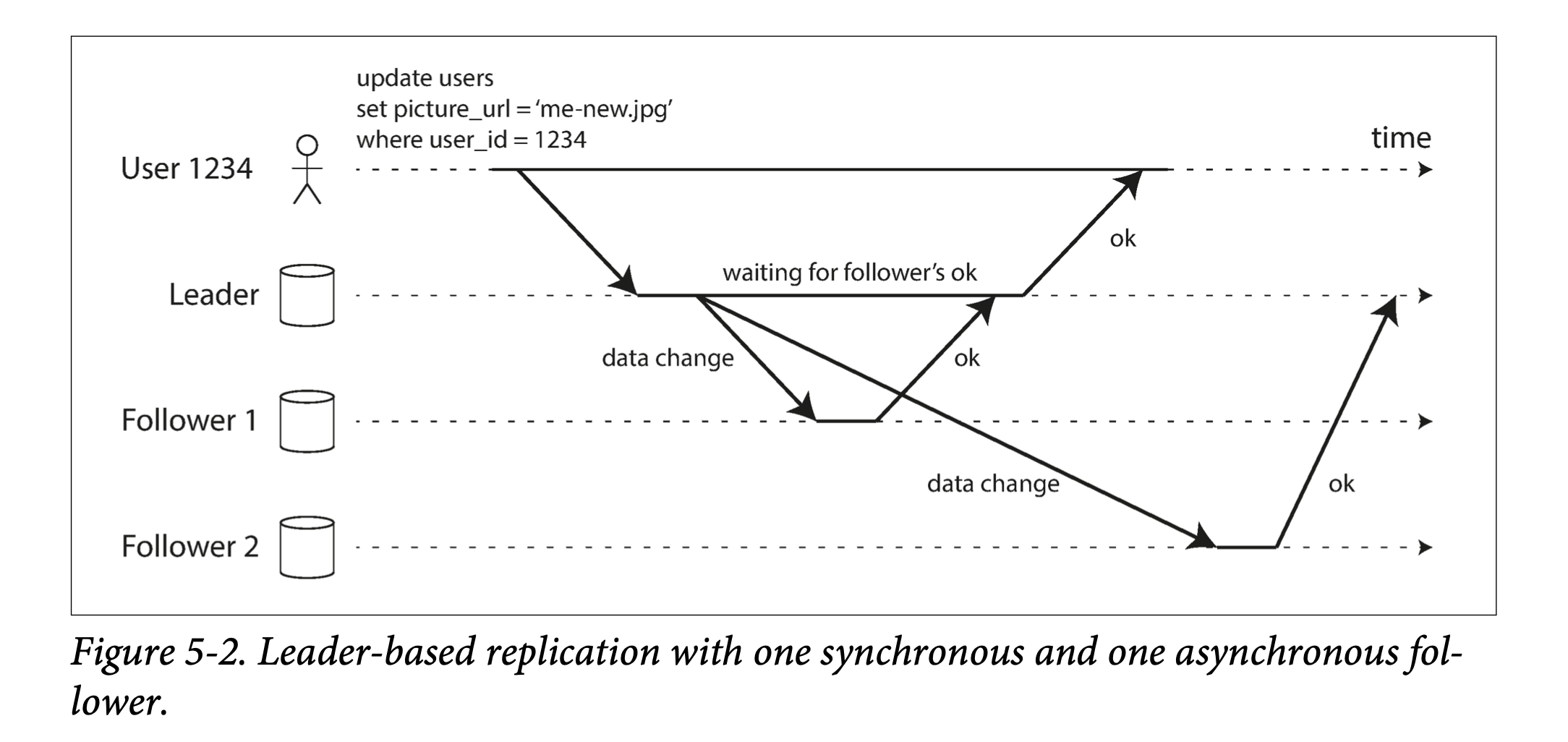
- Sync: leader waits for follower to finish update, then responde
- Cons: leader halts/waits for follower: if one follower fails, all nodes wait
- Remedy: semi-sync. make only one sync; make other follower node sync once the old sync follower fails
Setting up new follower
- Leader takes a snapshot
- Copy to the new follower
- Follower requests a log of all data change since the snapshot
- Follower process the backlog and “caught up”
Leader failover
- Determining that the leader has failed
- Choosing a new leader. : involve consensus problem.
- Reconfiguring the system to use the new leader.: route all request to new leader and need to tell older leader to stepdown if it ever comes back
Problems with failover
- Async writes on older leader not propergates to new leader
- Two nodes think they are leader at the same time
- What is the best timeout?
Replication Log
- Statement based(replicate execute UPDATE, DELETE ,etc.): not used today.
- Problems (non-deterministic statement, side effect, execution order)
- Write-ahead log (WAL) shipping:
- Problem: The main disadvantage is that the log describes the data on a very low level: a WAL con‐ tains details of which bytes were changed in which disk blocks.
-
Logical (row-based) log replication: a sequence of records describing writes to database tables at the granularity of a row:
- Trigger-based replication: bind application level code to database changes
- Problems: more overhead, bugs.
To be continued….